Frank at 2am: same fix, half the cost
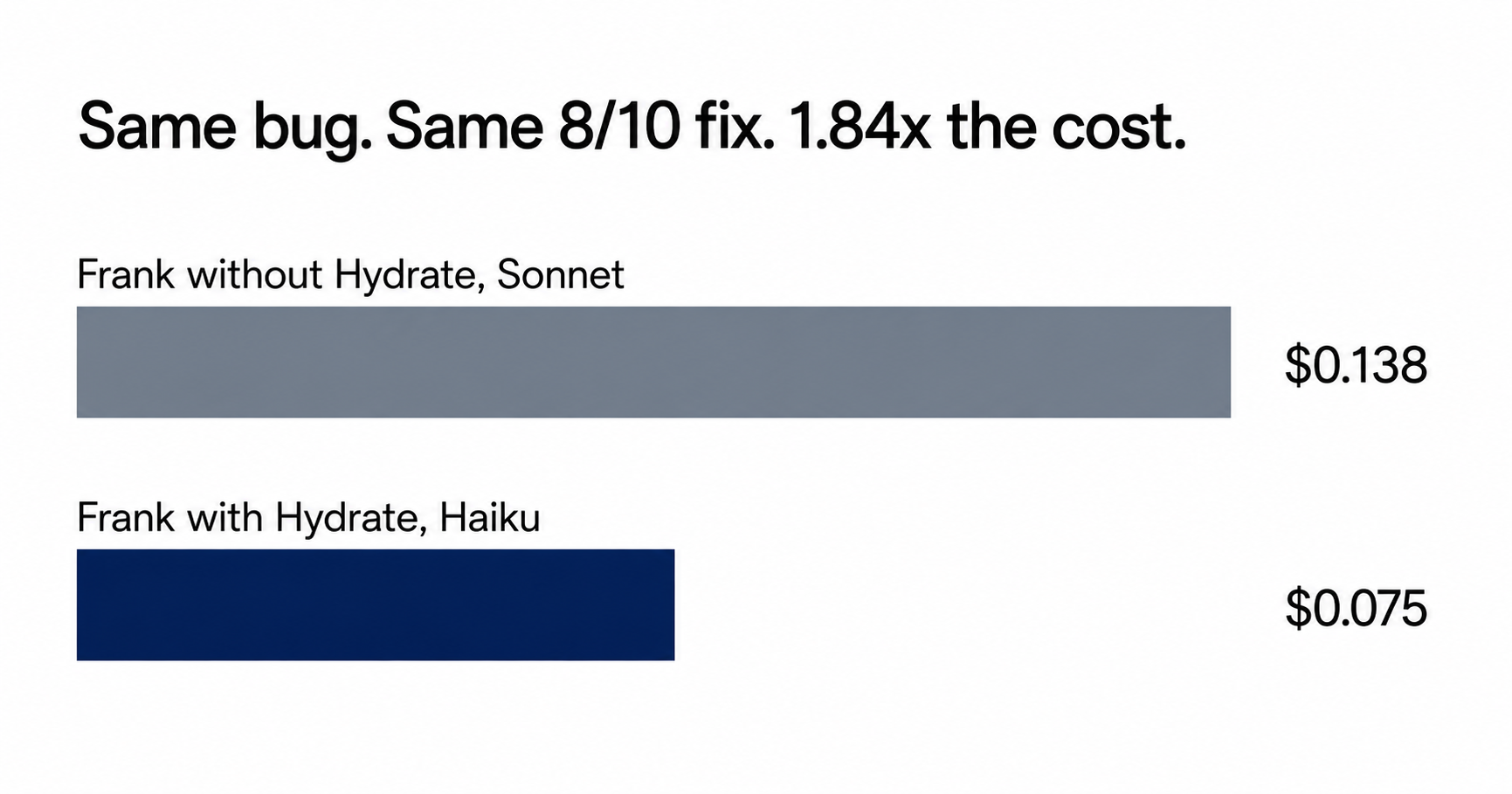
Narrative angle on the firefighter benchmark. Same bug, same 8/10 fix, same passing build. Haiku-with-memory cost $0.075. Sonnet-without cost $0.138. The whole cost story compressed into one on-call shift.
X / Twitter
Post 1 272 / 280
2am. Frank gets paged. Auth bypass live in production. He has never seen the codebase. Same bug. Same 8/10 fix. Same passing build. Frank with Hydrate (Haiku): $0.075 Frank without (Sonnet): $0.138 Memory did not make him smarter. It made the cheaper model sufficient.
Hook tweet. Best posted Tuesday to Thursday, 8 to 10am UK time. Reply with the LinkedIn version as a thread continuation.
Post 2 284 / 280
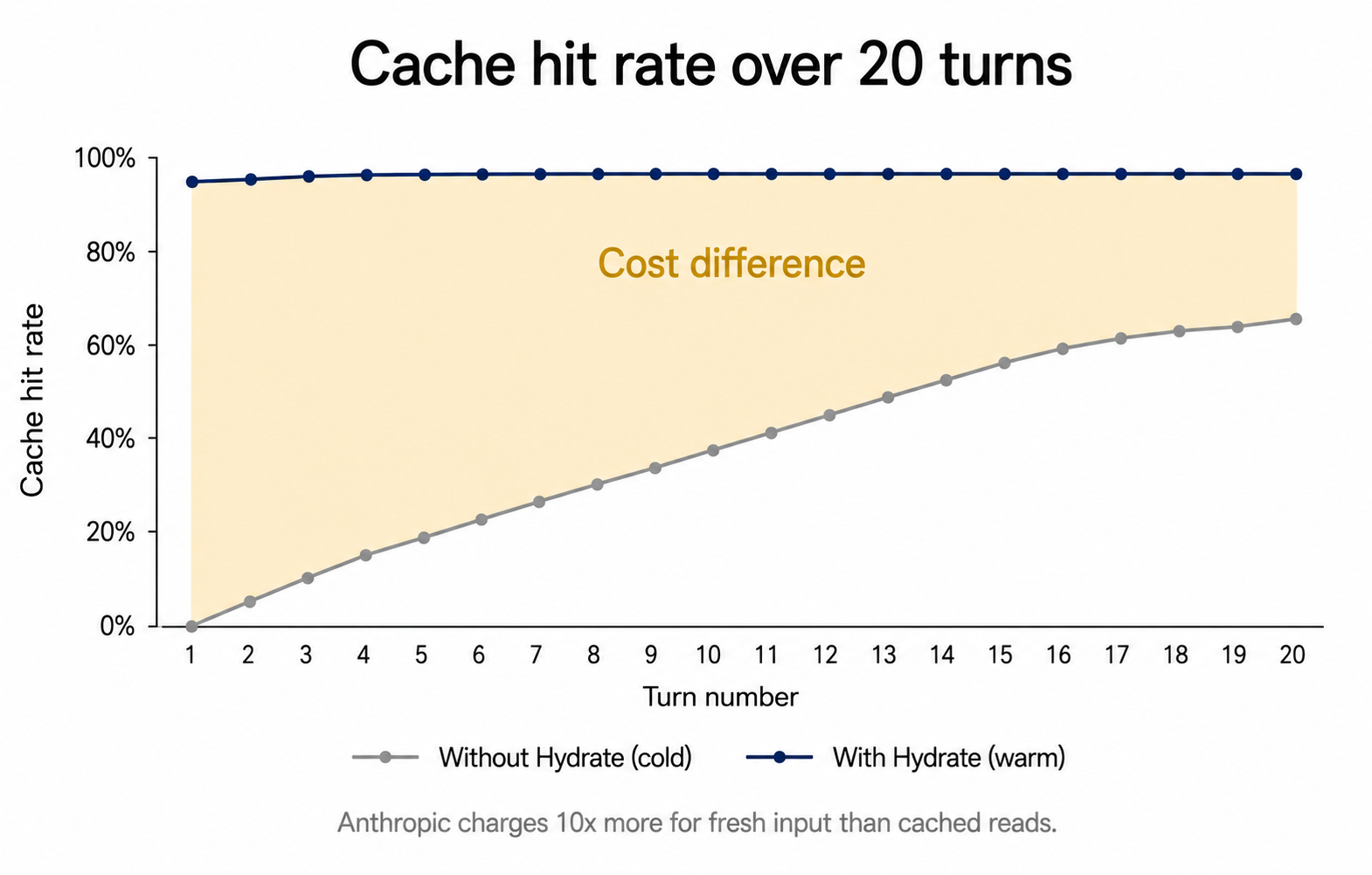
The mechanism is just cache. Sonnet fresh input: $3 per million tokens. Sonnet cached read: $0.30 per million. Ten times. Without memory, every session starts cold. Cache hit rate sits around 67%. With memory, context is warm before turn one. 97%. Whole cost story in two numbers.
Stat-led follow-up. Can stand alone or thread under the Frank tweet.
Post 3 267 / 280
Sonnet for new decisions. Haiku for established implementation. That is the whole rule. Hydrate is the bridge that makes Haiku viable on warm context. After your first sprint, roughly 80% of your sessions do not need frontier reasoning. They need frontier context.
Standalone rule tweet. Quotable. Pin candidate.
Post 2010 chars
A 2am incident response, twice. Same codebase, same bug, same grade. Different bill. I ran a benchmark called the firefighter test. An on-call engineer, Frank, gets paged. A security bypass was committed to production four hours ago and never reverted. Every authenticated endpoint is exposed. He has ten minutes to understand the architecture, find the bug, fix it, and tag a release. He has never seen the codebase. Two runs. Identical task. Identical automated grader. Frank with Hydrate found the bug in the right file on the first try, because the team's architectural context was injected before his first prompt. He ran on Haiku. Total session cost: $0.075. Score: 8/10. Frank without Hydrate explored. He found dead handler files, deleted them (a defensible cleanup, but out of scope for incident response), then found the actual bug. Two commits instead of one. He ran on Sonnet because cold discovery needs the bigger model. Total session cost: $0.138. Score: 8/10. Same fix. Same grade. 1.84 times cheaper. The finding I did not expect when I started this benchmark programme: memory does not primarily make agents smarter. It makes cheaper models viable. The mechanism is prompt cache. Anthropic charges roughly ten times more for fresh input than for cached reads. Without memory, every session starts cold and you pay fresh-input rates while the cache warms. With memory, prior context is injected, stable, and served from cache from turn one. I see roughly 67% cache hit rate without Hydrate. 97% with. Across every run in the benchmark programme. For a solo developer the practical rule simplifies. Sonnet for new decisions. Haiku for established implementation. After your first sprint, roughly 80% of your sessions are implementation against decisions you have already made. Those sessions do not need frontier reasoning. They need frontier context. And context, unlike reasoning, is something you can carry forward cheaply. Full benchmark data and methodology: gethydrate.dev/blog
Long-form. Best posted Tuesday or Wednesday, 7 to 9am UK or 7 to 9am Pacific. Lead with the cost-card image if you have it.
Bluesky
Post 1 269 / 300
2am. Frank's been paged. Auth bypass in production. He has never seen the codebase. Same bug. Same 8/10 fix. Same passing build. Frank-with-Hydrate (Haiku): $0.075 Frank-without (Sonnet): $0.138 Memory did not make him smarter. It made the cheaper model sufficient.
Same hook as X but uses the 300-char limit comfortably.
Mastodon
Post 607 / 500
A 2am incident response, run twice. Frank gets paged. Security bypass in production. He has never seen the codebase. Same task, same grader, two model paths. With Hydrate, he ran on Haiku. The team's architectural context was injected before his first prompt. He went straight to the right file. Cost: $0.075. Grade: 8/10. Without, he ran on Sonnet. Needed the bigger model for cold discovery. Found the bug, but explored first. Cost: $0.138. Grade: 8/10. Memory does not primarily make agents smarter. It makes cheaper ones sufficient. Full data: gethydrate.dev/blog/memory-not-smarter-cheaper-models
500-char Mastodon variant. Fediverse audience tolerates link drops better than X.
r/ClaudeAI
Title
I benchmarked the same on-call incident with and without memory injection. Same fix, half the cost.
Body
Sharing a finding from a benchmark programme I have been running on Hydrate, a memory layer for Claude Code.
**Setup:** containerised Claude Code session, simulated 2am page. Security bypass committed to production four hours earlier; the `protected()` JWT middleware closure in `main.go` was replaced with a passthrough. On-call engineer ("Frank") has never seen the codebase. Ten-minute window.
**Two runs, same task, same automated Sonnet-judged grader.**
Run A. Frank with Hydrate, on Haiku:
- Hook fired before turn one, injected team architectural context
- Went directly to `main.go`, identified the closure replacement
- One commit, correct fix, build green
- Session cost: $0.075
- Grade: 8/10
Run B. Frank without Hydrate, on Sonnet:
- No injected context, read sprint docs from repo
- Explored, found dead handler files in `internal/handlers/` (legacy from a restructure), cleaned those up first
- Eventually found the bug in `internal/projects/handler.go`
- Two commits, correct fix, build green
- Session cost: $0.138
- Grade: 8/10 (grader noted the dead-code detour as "defensible but out of scope")
Same outcome, 1.84 times cheaper. The expensive part is not the reasoning. It is the cold-start cache miss. Sonnet fresh-input is ten times the cached-read rate. Without memory, every session starts cold and you pay fresh rates while the cache warms.
Full methodology and the eleven other scenarios on the benchmarks page: https://gethydrate.dev/benchmarks
Curious whether others here have measured cache hit rates on long sessions versus short ones. The 67% (cold) vs 97% (warm) gap was bigger than I expected.
Reddit prefers technical depth and 'I measured X, here is the data' framing. Avoid posting at weekends.
r/golang
Title
Cost benchmark: Go REST API debugging with and without an MCP-injected memory layer
Body
I have been running benchmarks on a Go project with and without a memory layer (Hydrate) injected via MCP into Claude Code. Setup: standard Go REST API, JWT middleware, three-sprint codebase. Bug introduced. Auth middleware closure replaced with a passthrough. Two engineers tasked with finding and fixing. With memory injection (running on Haiku): - Architectural context loaded before first prompt - Engineer went straight to `main.go`, identified the closure swap - One commit, $0.075 Without memory injection (running on Sonnet): - Engineer read repo docs, explored - Found and cleaned up legacy `internal/handlers/` dead code first - Then found the bug in `internal/projects/handler.go` - Two commits, $0.138 Same fix, same grade from the automated reviewer. The economic difference came from prompt cache. Cold session was at 67% hit rate, warm session at 97%, and Anthropic charges ten times more for fresh input than for cached reads. So the warmer-context Haiku run beat the cold-context Sonnet run on price for the same outcome. Posting here because the project is Go end-to-end. Hydrate itself is a Go binary, the test harness is Go, the benchmark target was a Go API. In case anyone is interested in the methodology. Repo / benchmarks: https://gethydrate.dev/benchmarks
Lean technical for r/golang. Lead with Go-relevance. Keep marketing tone out.
Hacker News
Submission
Title
Memory doesn't make AI agents smarter. It makes cheaper ones viable.
URL
https://gethydrate.dev/blog/memory-not-smarter-cheaper-models
First comment
Author here. The headline is the finding I did not expect when I started. I designed a benchmark programme to answer "does memory improve AI agent quality?" and assumed the answer would be yes, with the value prop being fewer mistakes. Across 12 runs and 5 scenario types the quality improvement was real but smaller than I expected. What kept showing up consistently was a different effect: warm-context Haiku closes the quality gap to cold-context Sonnet on most implementation tasks, at roughly a quarter of the cost. The mechanism is just prompt cache. Anthropic charges roughly ten times more for fresh input than for cached reads. Cold sessions sit around 67% cache hit rate. Warm sessions (memory injected before turn one) sit around 97%. That gap, compounded across every turn of every session, is the entire economic story. Methodology, all 12 runs, and the firefighter scenario in detail are linked. Happy to answer questions about the test harness. It is containerised, automated grader, no human in the loop on either side.
dev.to / Hashnode
Article
Title
Memory doesn't make AI agents smarter. It makes cheaper ones viable.
Tags
ai, claudecode, productivity, costoptimization
Body (markdown)
*This is a cross-post of an article originally published at [gethydrate.dev](https://gethydrate.dev/blog/memory-not-smarter-cheaper-models).* At 2am, Frank gets paged. A security scanner has flagged production. `GET /api/v1/projects` is returning a full list of every project in the system, no authentication required. I ran this scenario twice. Both times, Frank fixed the bug. Both times, he scored 8/10. The only difference was cost. One Frank cost $0.075. The other cost $0.138. ## What I was trying to measure I have been building Hydrate, a memory layer for Claude Code. The short version: it injects prior session context before every prompt turn, and gives AI agents access to a shared team knowledge store via MCP tools. I had a hypothesis. Memory makes agents better. More context, fewer mistakes, higher quality output. That is not wrong. But it is not the main finding either. I ran 12 benchmarks across five different scenarios. Dev sprints. Multi-sprint team simulations. New developer onboarding. P0 incident response. Same project, same tasks, with and without Hydrate, measuring cost, quality, and cache hit rates at every step. The finding that kept repeating itself was not "memory prevents mistakes". It was "memory lets you use Haiku where you would otherwise need Sonnet". ## The cache hit rate is the whole story Anthropic charges different rates depending on whether a token comes from the prompt cache or arrives fresh. For Sonnet: $3.00 per million fresh input tokens, $0.30 per million cache-read tokens. For Haiku: $0.80 per million fresh, $0.08 per million cached. Ten to one, in both cases. When Hydrate injects prior session context before a prompt turn, that context is stable. It does not change. Anthropic's prompt cache serves it at the cheap rate on every subsequent turn. Without Hydrate, each new session starts cold, everything arrives fresh, and you pay the full rate until the cache warms up. In one of the early benchmarks, I noticed that without Hydrate, the first dev session ran at a 67% cache hit rate. Every Hydrate-enabled session in the same benchmark programme ran at 97 to 98%. That gap, 67% to 97%, is the entire cost story. Not a memory system making smarter decisions. Token pricing, compounded across every turn. [Continue reading at gethydrate.dev →](https://gethydrate.dev/blog/memory-not-smarter-cheaper-models)
Images
Image

Save the generated image as
0001-01-hero.png
Prompt
Editorial illustration, dark muted palette (deep navy, charcoal, single warm amber accent). A solo developer at a desk in a darkened room, lit only by the glow of a single laptop screen showing a terminal with a red error highlight. Behind them, an analogue clock on the wall reads 2:00. Style: clean, minimal, vector-illustration feel, similar to The Economist or Stripe Press editorial. No text on screen, no logos, no people facing the camera. Aspect ratio 16:9. The mood is competent, focused, deliberate. Not panicked.
Image
Save the generated image as
0001-02-cost-card.png
Prompt
Minimalist data visualisation, white background, generous margins. Two horizontal bars stacked vertically. Top bar labelled "Frank without Hydrate, Sonnet" filling roughly two thirds of the available width, in muted slate grey, with the value "$0.138" right-aligned. Bottom bar labelled "Frank with Hydrate, Haiku" filling roughly one third of the available width, in deep navy, with the value "$0.075" right-aligned. Title above: "Same bug. Same 8/10 fix. 1.84x the cost." No gridlines, no decorative elements, no shadows. Inter or Helvetica throughout. Aspect ratio 1.91:1 (LinkedIn and X feed-friendly).
Image
Save the generated image as
0001-03-cache-chart.png
Prompt
Clean line chart, white background. X-axis labelled "Turn number" from 1 to 20. Y-axis labelled "Cache hit rate" from 0% to 100%. Two lines plotted. One labelled "Without Hydrate (cold)" in light grey, starting around 0%, climbing slowly, plateauing near 67% by turn 20. One labelled "With Hydrate (warm)" in dark navy, starting near 95% on turn one and remaining flat near 97% across all turns. Soft amber fill between the two lines, labelled "Cost difference". Subtitle below chart: "Anthropic charges 10x more for fresh input than cached reads." No 3D, no shadows, no decorative elements. Inter or Helvetica throughout.